В этом руководстве я опишу, как создать систему парсинга книг на основе Django, поддерживающую различные категории и гибкую фильтрацию. Мы разберем структуру проекта, создание моделей, настройку административной панели и реализацию самого парсера. Это решение предназначено для автоматизации сбора данных с сайта, например, онлайн-магазина, и будет полезно для разработчиков, стремящихся улучшить свои навыки работы с Django.
Шаг 1: Создание моделей для категорий и книг
Первым шагом является создание двух моделей: category_book для категорий и book_pages для книг. Эти модели определяют структуру данных, которую мы будем собирать и хранить в базе данных.
Модель для категорий книг
from django.db import models
# Словарь для хранения типов фильтрации книг
dict_book = {
'Все книги': 'all_book',
'По популярности': 'popular',
'По новизне': 'news',
'Больше отзывов': 'reviews',
'Бестселлеры': 'bestseller',
'Рейтинг (от 4 звезд)': 'reiting'
}
class category_book(models.Model):
# Название категории
titleCategory = models.CharField(max_length=250, verbose_name='Название категории')
# Слаг для URL (генерируется автоматически)
slugCategory = models.CharField(max_length=250, verbose_name='Слаг заполняется автоматически', blank=True, null=True)
# URL категории на внешнем сайте
urlCategory = models.CharField(max_length=250, verbose_name='Ссылка на категорию из сайта')
# Флаг для выбора: только первая страница или вся категория
allCategoryBook = models.BooleanField(default=True, verbose_name='Только первая страница? Или вся категория.')
# Количество выгружаемых книг (опционально)
calcCategoryBook = models.IntegerField(verbose_name='Введите количество выгружаемых книг', blank=True, null=True, default=0)
# Тип сортировки книг
filterCategoryBook = models.CharField(
max_length=10,
choices=[(value, name) for name, value in dict_book.items()],
verbose_name='Тип сортировки книг'
)
def save(self, *args, **kwargs):
# Автоматическая генерация слага, если он не был задан
if not self.slugCategory:
self.slugCategory = custom_slugify(self.titleCategory)
super().save(*args, **kwargs)
def __str__(self):
return self.titleCategory
class Meta:
verbose_name = 'Категория'
verbose_name_plural = 'Категории'
Эта модель включает основные поля для работы с категориями книг. Поле titleCategory хранит название категории, а slugCategory автоматически генерируется на основе названия с помощью функции custom_slugify. Поле urlCategory содержит ссылку на соответствующую категорию на внешнем сайте, откуда будут парситься данные. Флаг allCategoryBook позволяет выбрать, нужно ли загружать только первую страницу категории или все страницы. calcCategoryBook указывает количество книг, которые следует выгрузить, а filterCategoryBook — тип сортировки (например, по популярности или новизне).
Модель для книг
class book_pages(models.Model):
# Изображение книги
imgBook = models.CharField(max_length=250, verbose_name='Изображение книги', null=True, blank=True)
# Название книги
titleBook = models.CharField(max_length=250, verbose_name='Название книги')
# Автор книги
autorBook = models.CharField(max_length=500, verbose_name='Автор книги', null=True, blank=True)
# Ссылка на книгу на внешнем сайте
linkBook = models.URLField(verbose_name='Ссылка')
# Старая цена
oldPricesBook = models.CharField(max_length=250, verbose_name='Старая цена', null=True, blank=True)
# Новая цена или просто цена
newPricesBook = models.CharField(max_length=250, verbose_name='Новая цена, или просто цена', null=True, blank=True)
# Категория книги
categoryBook = models.ForeignKey(category_book, on_delete=models.CASCADE, blank=True, null=True, verbose_name='Выберите категорию книги')
def __str__(self):
return self.titleBook
class Meta:
verbose_name = 'Книга'
verbose_name_plural = 'Книги'
Эта модель описывает данные, которые мы будем собирать для каждой книги. Она включает поля для хранения изображений, названий, авторов, ссылок, цен и связи с категорией. Поля oldPricesBook и newPricesBook предназначены для отображения изменения цен, что полезно для отслеживания скидок.
Шаг 2: Реализация функции транслитерации и генерации слага
Для автоматической генерации слага на основе названия категории нам понадобится функция транслитерации. Она преобразует кириллицу в латиницу, удаляет ненужные символы и форматирует текст для использования в URL.
TRANSLIT_DICT = {
'а': 'a', 'б': 'b', 'в': 'v', 'г': 'g', 'д': 'd',
'е': 'e', 'ё': 'e', 'ж': 'zh', 'з': 'z', 'и': 'i',
'й': 'i', 'к': 'k', 'л': 'l', 'м': 'm', 'н': 'n',
'о': 'o', 'п': 'p', 'р': 'r', 'с': 's', 'т': 't',
'у': 'u', 'ф': 'f', 'х': 'h', 'ц': 'ts', 'ч': 'ch',
'ш': 'sh', 'щ': 'sch', 'ъ': '', 'ы': 'y', 'ь': '',
'э': 'e', 'ю': 'yu', 'я': 'ya'
# Добавлены и заглавные буквы
}
def custom_slugify(text):
transliterated_text = ''.join(TRANSLIT_DICT.get(c, c) for c in text)
sanitized_text = transliterated_text.replace("'", "").replace('"', "").replace(',', '').replace(';', '').replace(':', '')
return sanitized_text.replace(' ', '-').lower()
Эта функция сначала транслитерирует текст на основе словаря TRANSLIT_DICT, затем удаляет символы, которые могут вызвать проблемы в URL, и заменяет пробелы на дефисы.
Шаг 3: Реализация парсера книг с поддержкой категорий и фильтров
Основная логика парсера реализована в классе views_pages. Этот класс позволяет настроить парсер для работы с конкретной категорией, определяя URL, количество книг и тип сортировки.
import requests
from bs4 import BeautifulSoup
from book.models import book_pages, category_book
class views_pages:
def __init__(self, category):
self.category_book_item = category
self.base_url = category.urlCategory
self.all_book = category.allCategoryBook
self.nums_book = category.calcCategoryBook
self.sort = category.filterCategoryBook
def number_str(self):
print(self.category_book_item, self.base_url)
if self.all_book != True:
html = requests.get(self.base_url).text
soup = BeautifulSoup(html, 'html.parser')
nums = soup.find_all('span', class_='pagination__text')
last_nums_pages = None
for nums_links in nums:
last_nums_pages = nums_links
nums_pages = last_nums_pages.get_text(strip=True)
print('Выбрано несколько страниц', nums_pages)
else:
nums_pages = 1
print('Выбрана одна страница')
return nums_pages
def parser_boock(self, nums_pages):
sort_options = {
'all_book': '',
'popular': '&sortPreset=popularity',
'news': '&sortPreset=newness',
'reviews': '&sortPreset=reviewsDesc',
'bestseller': '&filters%5BonlyBestseller%5D=1',
'reiting': '&filters%5BratingStars%5D=4&filters%5BratingStars%5D=5',
}
sort_param = sort_options.get(self.sort, '')
for pages in range(1, int(nums_pages)+1):
base_url_patterns = self.base_url + '?page=' + str(pages) + sort_param
html = requests.get(base_url_patterns, timeout=10).text
soup = BeautifulSoup(html, 'html.parser')
articls = soup.find_all('article', class_='product-card product-card product')
count = 0
print(base_url_patterns)
for i, items in enumerate(articls):
if self.nums_book != 0:
if count < int(self.nums_book):
url = items.find('a', class_='product-card__picture')
url_print = url.get('href')
url_final = str('https://www.chitai-gorod.ru' + str(url_print))
title = soup.find_all('div', class_='product-title__head')[i]
title_book = title.get_text(strip=True)
img = soup.find_all('img', class_='product-picture__img')[i]
img_book = img.get('data-srcset')
if img.get('data-srcset'):
img_str = img_book.split('?width=400&height=560&fit=bounds 2x')
img_str_link = img_str[0]
else:
img_str = img.get('src')
img_str_link = img_str
old_prices = items.find('div', class_='product-price__old')
if old_prices:
old_prices_text = old_prices.get_text(strip=True)
else:
old_prices_text = ''
sale_prices = items.find('div', class_='product-price__value')
if sale_prices:
sale_prices_text = sale_prices.get_text(strip=True)
else:
sale_prices_text = ''
autor = items.find('div', class_='product-title__author')
if autor:
autor_text = autor.get_text(strip=True)
else:
autor_text = 'Автор не указан'
if title_book:
bookSite = book_pages.objects.filter(titleBook=title_book).first()
if bookSite:
if (bookSite.autorBook != autor_text or
bookSite.linkBook != url_final or
bookSite.oldPricesBook != old_prices_text or
bookSite.newPricesBook != sale_prices_text or
bookSite.categoryBook != self.category_book_item):
bookSite.imgBook = img_str_link
bookSite.autorBook = autor_text
bookSite.linkBook = url_final
bookSite.oldPricesBook = old_prices_text
bookSite.newPricesBook = sale_prices_text
bookSite.categoryBook = self.category_book_item
bookSite.save()
else:
print("Запись уже содержит актуальные данные.")
else:
book_pages.objects.create(
imgBook=img_str_link,
titleBook=title_book,
autorBook=autor_text,
linkBook=url_final,
oldPricesBook=old_prices_text,
newPricesBook=sale_prices_text,
categoryBook = self.category_book_item,
)
else:
print('Одно из полей не имеет значений')
count += 1
else:
break
elif self.nums_book == 0:
url = items.find('a', class_='product-card__picture')
url_print = url.get('href')
url_final = str('https://www.chitai-gorod.ru' + str(url_print))
title = soup.find_all('div', class_='product-title__head')[i]
title_book = title.get_text(strip=True)
img = soup.find_all('img', class_='product-picture__img')[i]
img_book = img.get('data-srcset')
if img.get('data-srcset'):
img_str = img_book.split('?width=400&height=560&fit=bounds 2x')
img_str_link = img_str[0]
else:
img_str = img.get('src')
img_str_link = img_str
old_prices = items.find('div', class_='product-price__old')
if old_prices:
old_prices_text = old_prices.get_text(strip=True)
else:
old_prices_text = ''
sale_prices = items.find('div', class_='product-price__value')
if sale_prices:
sale_prices_text = sale_prices.get_text(strip=True)
else:
sale_prices_text = ''
autor = items.find('div', class_='product-title__author')
if autor:
autor_text = autor.get_text(strip=True)
else:
autor_text = 'Автор не указан'
if title_book:
bookSite = book_pages.objects.filter(titleBook=title_book).first()
if bookSite:
if (bookSite.autorBook != autor_text or
bookSite.linkBook != url_final or
bookSite.oldPricesBook != old_prices_text or
bookSite.newPricesBook != sale_prices_text or
bookSite.categoryBook != self.category_book_item):
bookSite.imgBook = img_str_link
bookSite.autorBook = autor_text
bookSite.linkBook = url_final
bookSite.oldPricesBook = old_prices_text
bookSite.newPricesBook = sale_prices_text
bookSite.categoryBook = self.category_book_item
else:
print("Запись уже содержит актуальные данные.")
else:
book_pages.objects.create(
imgBook=img_str_link,
titleBook=title_book,
autorBook=autor_text,
linkBook=url_final,
oldPricesBook=old_prices_text,
newPricesBook=sale_prices_text,
categoryBook = self.category_book_item,
)
else:
print('Одно из полей не имеет значений')
else:
print('Значение не корректное')
return
def run(self):
nums_pages = self.number_str()
data = self.parser_boock(nums_pages)
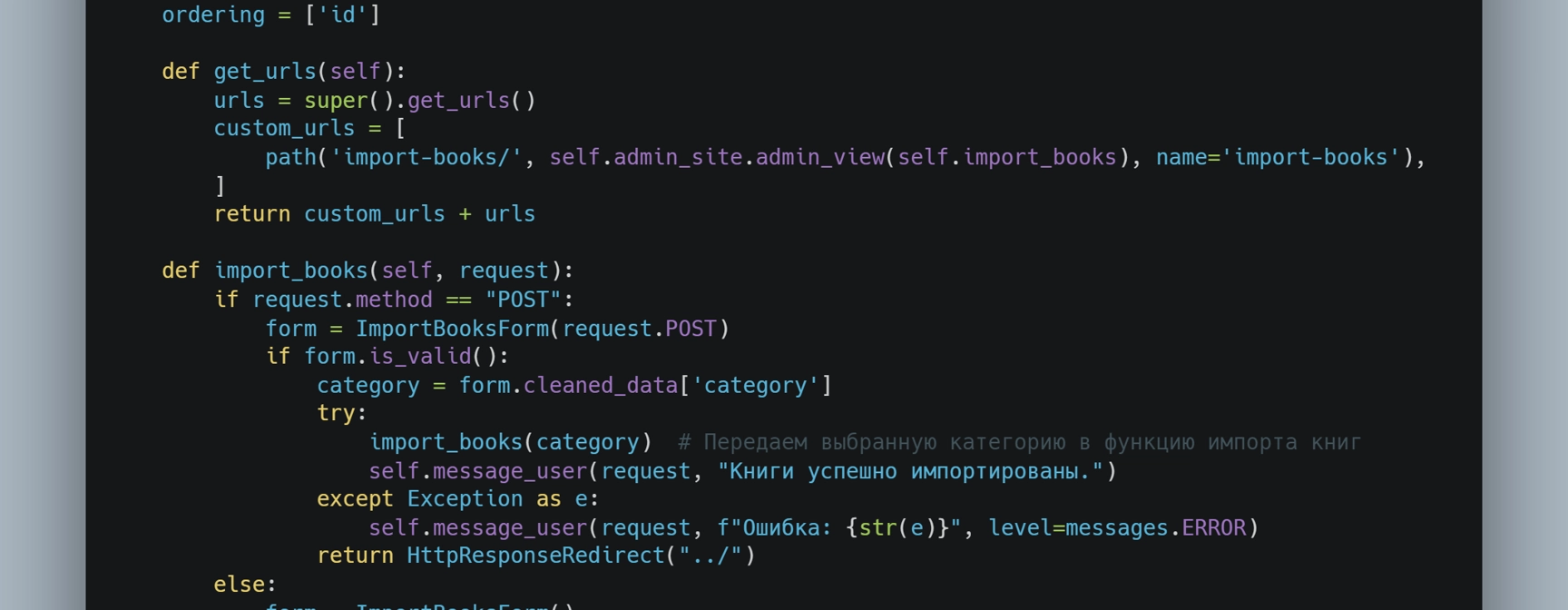
def import_books(category):
parser = views_pages(category)
parser.run()
Шаг 5: Настройка URL маршрутизации
Для того чтобы пользователи могли взаимодействовать с вашим приложением, необходимо настроить URL маршрутизацию. Мы добавим URL-шаблоны для управления категориями и книгами.
Настройка URL для управления книгами
Создайте файл urls.py в вашем приложении, если его еще нет, и добавьте следующие маршруты:
from django.urls import path
from .views import CategoryListView, BookListView, CategoryDetailView, BookDetailView
urlpatterns = [
path('', CategoryListView.as_view(), name='category-list'),
path('category/<slug:slug>/', CategoryDetailView.as_view(), name='category-detail'),
path('book/<int:pk>/', BookDetailView.as_view(), name='book-detail'),
]
Этот код настраивает следующие маршруты:
category-list— для отображения списка всех категорий.category-detail— для отображения книг в конкретной категории.book-detail— для просмотра подробностей о книге.
Настройка URL для административной панели
В файле urls.py проекта добавьте маршрут для административной панели, если он еще не добавлен:
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('books/', include('book.urls')), # Подключение маршрутов для приложения books
]
Шаг 6: Создание представлений (Views)
Создайте представления для обработки запросов пользователей. Мы будем использовать класс-based views (CBV) для упрощения работы.
Представления для категорий и книг
Создайте файл views.py в вашем приложении и добавьте следующие классы:
from django.views.generic import ListView, DetailView
from .models import category_book, book_pages
class CategoryListView(ListView):
model = category_book
template_name = 'category_list.html'
context_object_name = 'categories'
class CategoryDetailView(ListView):
model = book_pages
template_name = 'category_detail.html'
context_object_name = 'books'
def get_queryset(self):
return book_pages.objects.filter(categoryBook__slugCategory=self.kwargs['slug'])
class BookDetailView(DetailView):
model = book_pages
template_name = 'book_detail.html'
context_object_name = 'book'
Шаблоны для представлений
Создайте папку templates внутри вашего приложения и добавьте следующие шаблоны:
- category_list.html
{% extends "base.html" %}
{% block content %}
<h1>Категории книг</h1>
<ul>
{% for category in categories %}
<li><a href="{% url 'category-detail' slug=category.slugCategory %}">{{ category.titleCategory }}</a></li>
{% endfor %}
</ul>
{% endblock %}
2. category_detail.html
{% extends "base.html" %}
{% block content %}
<h1>Книги в категории "{{ category.titleCategory }}"</h1>
<ul>
{% for book in books %}
<li>
<a href="{% url 'book-detail' pk=book.pk %}">
<img src="{{ book.imgBook }}" alt="{{ book.titleBook }}">
{{ book.titleBook }} - {{ book.newPricesBook }}
</a>
</li>
{% endfor %}
</ul>
{% endblock %}
3. book_detail.html
{% extends "base.html" %}
{% block content %}
<h1>{{ book.titleBook }}</h1>
<img src="{{ book.imgBook }}" alt="{{ book.titleBook }}">
<p>Автор: {{ book.autorBook }}</p>
<p>Старая цена: {{ book.oldPricesBook }}</p>
<p>Новая цена: {{ book.newPricesBook }}</p>
<a href="{{ book.linkBook }}" target="_blank">Посмотреть книгу</a>
{% endblock %}
Шаг 7: Тестирование и отладка
Теперь, когда основная структура готова, вам нужно протестировать систему:
-
Проверьте модели: Убедитесь, что модели правильно сохраняют и обновляют данные. Попробуйте создать несколько записей через административную панель и убедитесь, что они отображаются в вашем приложении.
-
Проверьте парсер: Запустите парсер и проверьте, что он правильно собирает данные. Убедитесь, что данные отображаются корректно на веб-страницах.
-
Проверьте представления и шаблоны: Убедитесь, что представления правильно обрабатывают запросы, и шаблоны корректно отображают данные.
-
Тестирование в разных браузерах: Проверьте отображение страниц в различных браузерах, чтобы убедиться, что все работает корректно.
Шаг 8: Улучшения и расширения
Когда основная система готова, вы можете подумать о следующих улучшениях:
-
Поддержка дополнительных фильтров: Расширьте систему фильтрации книг, добавив больше опций для сортировки и фильтрации.
-
Оптимизация производительности: Оптимизируйте парсер для повышения производительности и минимизации времени обработки.
-
Интерфейс пользователя: Улучшите интерфейс пользователя, добавив больше стилей и интерактивных элементов.
-
Аналитика и отчеты: Добавьте функциональность для сбора и отображения аналитики, такой как количество книг в каждой категории, популярность книг и т.д.
-
Автоматическое обновление данных: Настройте регулярные задачи для автоматического обновления данных о книгах.
Эти улучшения помогут сделать вашу систему более гибкой и мощной, предоставляя пользователям лучшие возможности для работы с книгами и категориями.
Написать комментарий