Сегодня я провел важное обновление моего парсера данных, которое значительно улучшает его функциональность и эффективность. В этой статье я расскажу о том, что именно было сделано и почему это так важно.
Проблема с дублирующимися данными
Когда я только начинал разработку парсера, одной из основных задач была автоматическая сборка данных с различных веб-ресурсов. Парсер отлично справлялся с задачей по сбору данных о книгах: он собирал информацию о названии, авторе, цене и других характеристиках. Однако по мере увеличения объема данных возникла проблема: если книга уже была в базе данных, парсер просто добавлял её снова, создавая дублирующиеся записи. Это приводило к засорению базы данных, снижало производительность и затрудняло работу с информацией.
Решение: Проверка наличия книги в базе данных
Чтобы решить эту проблему, я добавил в парсер новую функцию, которая проверяет наличие книги в базе данных перед добавлением новой записи. Это было реализовано с помощью простого, но эффективного алгоритма:
-
Поиск книги по названию: Парсер сначала проверяет, существует ли запись с таким же названием книги в базе данных. Если книга найдена, это означает, что она уже была ранее добавлена.
-
Сравнение данных: Если книга существует в базе, парсер сравнивает текущие данные с уже существующими записями. Например, если цена книги изменилась или обновилась информация о её авторе, парсер это заметит.
-
Обновление записи: В случае, если обнаружены изменения в данных, парсер обновляет существующую запись, заменяя старые данные новыми. Если же данные совпадают, никаких действий не производится, что позволяет избежать ненужных операций и поддерживать базу данных в актуальном состоянии.
-
Создание новой записи: Если книга не найдена в базе, парсер создаёт новую запись, сохраняя все необходимые данные.
Преимущества нового подхода
Это обновление решает сразу несколько проблем:
-
Избежание дублирования данных: Теперь каждая книга представлена в базе данных только одной записью, что упрощает управление данными.
-
Поддержание актуальности информации: Благодаря регулярной проверке и обновлению данных, база данных всегда содержит самую свежую информацию.
-
Увеличение производительности: Из-за уменьшения количества дублирующих записей, работа с базой данных стала быстрее и эффективнее.
Заключение
Это обновление может показаться небольшим, но оно значительно улучшает общий процесс работы парсера. Подобные улучшения являются важным шагом на пути к созданию более эффективных и умных систем обработки данных. В будущем я планирую добавить дополнительные функции для ещё большего улучшения работы парсера, такие как оптимизация запросов и улучшение алгоритмов обработки данных.
Если у вас есть вопросы или вы хотите узнать больше о работе парсера, пишите в комментариях или свяжитесь со мной напрямую. Я всегда рад поделиться опытом и обсудить новые идеи!
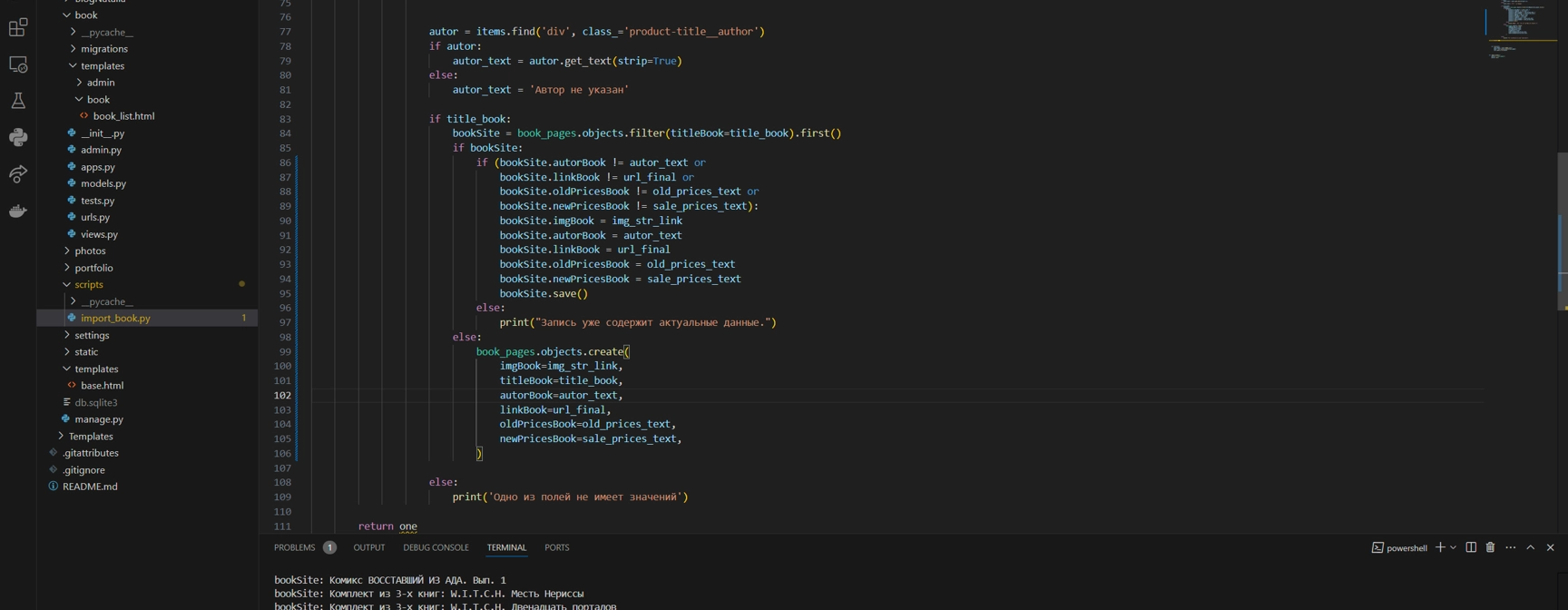
Примененный код:
if title_book:
bookSite = book_pages.objects.filter(titleBook=title_book).first()
if bookSite:
if (bookSite.autorBook != autor_text or
bookSite.linkBook != url_final or
bookSite.oldPricesBook != old_prices_text or
bookSite.newPricesBook != sale_prices_text):
bookSite.imgBook = img_str_link
bookSite.autorBook = autor_text
bookSite.linkBook = url_final
bookSite.oldPricesBook = old_prices_text
bookSite.newPricesBook = sale_prices_text
bookSite.save()
else:
print("Запись уже содержит актуальные данные.")
else:
book_pages.objects.create(
imgBook=img_str_link,
titleBook=title_book,
autorBook=autor_text,
linkBook=url_final,
oldPricesBook=old_prices_text,
newPricesBook=sale_prices_text,
)
else:
print('Одно из полей не имеет значений')
Написать комментарий